



I got an email yesterday from a client, stating his concern that there’s no way he could outrank his competitors or have a better search engine ranking because his website is full of html errors.
Does it really help a site improve in search engine ranking?
Search engines do follow W3C standards so theoretically, it helps. It’s a different story if your site is FULL of HTML errors. Sometimes, it’s not just on errors but also on how you treat your HTML tags. In such a competitive SEO world, errors do count against you.
Let me give you a simple scenario. We have 2 blogs with the same content. One is coded semantically while the other isn’t. Here are the contents:
Title: Lorem Ipsum
Paragraph: Lorem ipsum dolor sit amet, consectetuer adipiscing elit. Duis bibendum, mi in dignissim aliquam, orci lacus tempor eros, in iaculis magna arcu sit amet est. Lorem Ipsum. Curabitur pretium erat in velit. Aliquam imperdiet. Lorem Ipsum. Donec laoreet ultrices leo. Cras tempor ultricies risus. Nam ut lectus volutpat est sollicitudin tristique. In mattis mollis quam. Vivamus commodo pellentesque elit. Lorem ipsum. Curabitur sit amet tellus vel diam egestas porttitor. Pellentesque habitant morbi tristique senectus et netus et malesuada fames ac turpis egestas. Lorem ipsum.

For example your target keyword is “Lorem ipsum”. The blog that will be coded semantically will be using the tag for the Title and the tag for the paragraph.
The other blog will be using the tag for both the title and the paragraph. In the context of keywords, search engines rank your keywords based on their importance.
So if the 2 blogs are the only Web sites in the World Wide Web, which one do you think will rank higher?
Search engines also treat lists differently from paragraphs. Many validation errors I’ve encountered were related to the misuse of unordered and ordered lists (UL and OL).
Again, this will be a point against you if your competitor had used lists correctly.
The Google representative may have said that Googlebot separates code from content, but in my opinion, the hierarchy is still there.
Headers and lists are more important than paragraphs, etc. So when the content was separated, it could be that Googlebot brought along with it the information on how the keywords were treated.
IMHO, it’s a good practice to always validate your site with the W3C standards. It’s even better if you know how to treat your HTML tags semantically. It won’t just benefit search engines, but your visitors as well. Having a standards compliant site means that you can reach the widest possible audience since most Web browsers adhere to standards.
What Google has to say about HTML Validation:
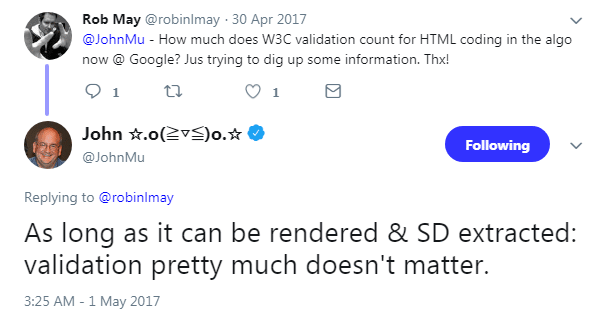
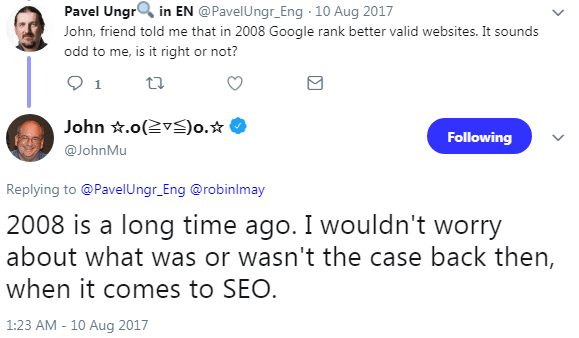
It looks like Google does not give much attention to HTML validation. Afterall, the internet is full of validation errors and it never broke down. But keeping those errors to a minimum will definitely help in:
- Optimizing Crawl Rate
- Optimize Browser Compatibility
- Give your visitors a good browsing experience
- Ensuring your pages view and function properly
- Keep in mind that invalid HTML in the <head> section, will break your Hreflang.
So, does HTML Validation Matter?
Most webpages online are not affected by poor HTML coding, but again, you never know when such elements would become a vital element in your website’s organic success.
Try to minimize your HTML errors to an extent, but definitely do not waste a lot of time fixing every single error for now.
